Hvernig á að búa til gagnleg gervigreindar forrit

Til að búa til gagnleg gervigreindar forrit er gott að skilja hvernig gervigreind virkar og hvernig best er að nota hana. Í þessari grein útskýrum við gervigreind og gefum innsýn í hvernig á að búa til sérsniðin forrit.
Þú munt sjá hvað er mögulegt að gera með með gervigreind sem er tilbúin til notkunar. Þú munt einnig læra hvað gæti takmarkað þig og hvernig hægt er að vinna með það. Kannski færðu hugmyndir um hvernig hægt er að nota gervigreindar forrit í þínu starfi.
Vonandi verður greinin þér innblástur en við munum sýna dæmi um hvernig við höfum samþætt LLM ( stór gervigreindar líkön) í mismunandi forritum í lok þessarar greinar.
Hvað er gervigreind?
AI stendur fyrir Gervigreind, sem vísar til eftirlíkingar á mannlegum upplýsingaöflun með vélum, sérstaklega tölvukerfum. Venjulega þegar við vísum til gervigreindar erum við í raun að tala um GPT forrit.
GPT stendur fyrir Generative Pretrained Transformers og vísar til tegundar sem notar spuna arkitektúr. Þetta er djúpnámslíkana arkitektúr sem er fyrst og fremst notaður fyrir náttúruleg málvinnslu verkefni.
Hvernig virka stór tungumála líkön?
GPT líkön eru þjálfuð í miklu magni af textagögnum og geta búið til mannlegan texta byggt á inntakinu sem þau fá. Vegna mikils magns gagna sem þessi líkön eru þjálfuð á eru þau einnig nefnd Stór tungumála líkön eða LLM ( e. Large Language Models).
“Pretrained“ þátturinn í skammstöfuninni GPT vísar til þess að þessi líkön eru upphaflega þjálfuð á miklu magni texta gagna með því að nota kennslutækni án eftirlits. Í þessum forþjálfunarfasa lærir líkanið að spá fyrir um næsta orð í textaröð miðað við samhengið á undan. Þetta gerir líkaninu kleift að fanga margs konar tungumála mynstur og merkingarfræði.
„Geranda“ hlutinn í skammstöfuninni GPT táknar að þessi líkön geta búið til viðeigandi texta í réttu samhengi sem byggir á skilaboðum eða fyrirmælum sem eru gefin. Þeir ná þessu með því að nota þekkinguna sem lærðist við forþjálfunina til að spá fyrir um líklegasta næsta orð eða röð orða miðað við samhengið.
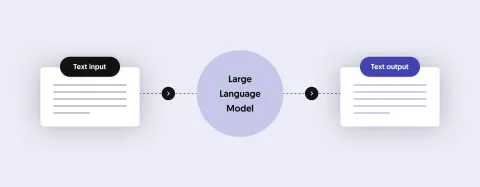
Þegar þú vilt búa til gervigreind forrit skaltu hugsa um LLM sem hugbúnað sem getur „talað“, sem þýðir að það getur búið til málfræðilega réttar setningar af skynsemi.
Auðvitað getur slíkt líkan aðeins talað um það sem það "þekkir", sem þýðir að það þekkir það sem það er þjálfað á.
Hvernig eru LLMs líkön þjálfuð? Er gagnlegt að gera þetta sjálfur?
Þjálfun á stóru tungumálalíkani getur verið krefjandi og tímafrekt verkefni. Það krefst umtalsverðra tíma af vinnu við hugbúnaðinn og mikillar þekkingar á þjálfunar málum fyrir kerfið. Þjálfunarlíkön með milljónum eða milljörðum breyta er dýrt og tímafrekt verkefni.
Einnig er þörf á miklu magni af hágæða textagögnum frá ýmsum aðilum og söfnun og forvinnsla slíkra gagnasafna krefst venjulega verulegs átaks til að tryggja gæði og fjölbreytileika gagnanna.
Ef nægjanleg innviði, fjármagn, tími og gögn eru fyrir hendi, er þjálfun venjulega gerð með því að nota blöndu af námsaðferðum með og án eftirlits. Fyrir vikið uppgötvast innri merkingarfræðileg og rökleg tengsl milli þátta í gagnasafni sem eru notuð þegar svör við inntaki gagna eru mynduð.

Hins vegar eru fullt af fyrirfram þjálfuðum almennum líkönum í boði sem hægt er að nota í stað þess að þjálfa eigin líkan. Þau frægustu eru líklega frá OpenAI og Mistral AI.
Oftast er mun áhrifaríkara að nota forþjálfað módel með gögnum frekar en að þjálfa upp módel með þínum eigin gögnum.
Hvernig get ég best notað núverandi LLMs?
Stór tungumálalíkön geta aðeins „talað“ um efni (gögn) sem þau voru þjálfuð í að nota.
Til þess að svara spurningum um mismunandi efni verða þessi gögn að berast til líkansins áður en spurningin er spurð. Þetta ferli er nefnt „nám í samhengi“.
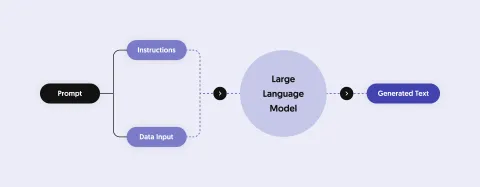
Til að gera gervigreind þinni kleift að tala um tiltekið efni þarftu að senda viðeigandi upplýsingar til líkansins áður en þú hefur samskipti við það.
Auk þess að senda gögn í stórt tungumálalíkan sendir þú venjulega leiðbeiningar til gagnalíkans sem lýsir því hvernig líkanið ætti að bregðast við.
Dæmi um slíkar leiðbeiningar eru tónn sem þú vilt nota eða takmarka efni sem kerfið ætti að svara.
Hversu mikið af gögnum geta LLMs notað?
Fræðilega séð geta LLMs notað ótakmarkað magn af gögnum. Gögn sem send eru til Stórra tungumálalíkana eru nefnd"tákn" ( e. tokens).
Það eru til gerðir sem geta séð um mjög mikinn fjölda tákna. Hins vegar, því fleiri gögn sem þú sendir til líkansins, því meira eykst flækjan til að reikna út skynsamleg svör.
Þess vegna bregðast líkön sem skilja flóknari gögn hægar við og eru dýrari í rekstri í samanburði við líkön sem skilja aðeins einfaldari gögn.
Því einfaldara sem verkefnið fyrir LLM er, því hraðar getur það brugðist við og þannig er hægt er að ná betri árangri.
Ef þú forvinnur inntakið og dregur úr upplýsingum á þann hátt að aðeins viðeigandi gögn berist til LLM geturðu búið til mun skilvirkara gervigreindar forrit.
Við þurfum góða verkfræði til að búa til góð gervigreindar forrit!
Til að halda verkefnum einföldum og hröðum fyrir þín forritin þarftu að vinna inntaks og úrtaksgögn á snjallan hátt.
Algeng venja er að skipta gervigreindarverkefnum í undirverkefni sem auðveldara er að vinna úr.
Þetta er best útskýrt með dæmi. Hugsaðu um forrit sem líkir eftir ferðaskrifstofu.
- Fyrsta verkefni ferðaskrifstofunnar væri að finna út hvert og hvenær einstaklingur vill ferðast.
- Annað verkefnið væri að finna (sækja) viðeigandi starfsemi fyrir áfangastað og tímabil.
- Þriðja verkefnið væri að hafa samráð við viðskiptavininn til að velja það besta úr tiltækum áfangastöðum.
Ofangreint verkefni er hægt að búa til sem forrit. Verk eitt og þrjú er hægt að framkvæma með gervigreind sem fær réttar leiðbeiningar og gögn. Verkefni tvö væri venjulegt gagnaöflunar verkefni.
Þessi aðferð er oft kölluð Retrieval Based Augmentation (RAG) og er algeng til að gera gervigreindar forritum kleift að starfa í stórum gagnasöfnum (til dæmis gagnagrunni fyrir ferðaþjónustu).

Hagræðing gagna fyrir fjöltyngt gervigreindar spjallmenni
Einn af viðskiptavinum okkar er "Insel Mainau", fræg blómaeyja í Bodenvatni í Suður-Þýskalandi. Á heimasíðu sinni birta þeir dagatal þar sem hægt er að lesa hvaða blóm blómstra í hverjum mánuði á eyjunni.
Textinn er á þýsku og ef þú reiknar út fjölda tákna fyrir undirsíður allra 12 mánaða ársin færðu vel yfir 20.000 tákn. Þessi tala jafngildir um 60.000 stöfum sem eru um 13.000 orð. Þetta er of mikið efni fyrir venjuleg gervigreindar forrit og vinnsla þessa gagnamagns væri of kostnaðarsöm.
Því minnkuðum við innihaldið með því að stytta það og fjarlægja öll óþarfa orð. Með þessari aðferð tókst okkur að koma fjölda tákna fyrir allar 12 síðurnar niður í 4.000.
Frumtexti fyrir marsmánuð
Was blüht im März auf der Insel Mainau?Im März freuen wir uns auf der Insel Mainau über das Comeback der Krokusse, Narzissen und Kamelien. Doch nicht nur das, denn auch die ersten Schmetterlinge haben bereits ihre Flügel entfaltet und tanzen munter durch die Lüfte.Seit 1973 ist die Orchideenschau im Palmenhaus der traditionelle Auftakt der blühenden Höhepunkte auf der Insel Mainau. Über 3.000 exotische Orchideen-Schönheiten in ihrer erstaunlichen Vielfalt an Formen und Farben werden ausgestellt. Entdecken Sie die lebendigen Farben von Phalaenopsis-, Vanda- und Cattleya-Orchideen sowie botanische Raritäten, die von unseren Gärtnern kunstvoll arrangiert werden....Minnkaður texti fyrir marsmánuð
MärzInsel Mainau erblüht vielfältigen Farbenspiel. Krokusse, Narzissen Kamelien bringen Frühling zurück, begleitet ersten flatternden Schmetterlingen. Traditionelle Orchideenschau Palmenhaus zeigt 3.000 exotische Orchideen faszinierenden Formen Farben. Märzenbecher kündigen weißen Blüten Ende Winters, Kamelien rosafarbenen, roten weißen Tönen Ufergarten blühen. ...
Tákn: 297
Stafir: 927
Eins og sjá má af dæminu fyrir marsmánuð hér að ofan var textinn minnkaður til muna. Ennfremur virkar minni textinn ekki lengur fyrir lesendur. Hins vegar, fyrir gervigreind skiptir þetta ekki máli, þar sem það spáir einfaldlega fyrir um orð byggt á inntaki með því að nota þjálfað mynstur þess.
Þegar gögn eru send í stórt tungumálalíkan er algengt að fjarlægja öll óþarfa orð og jafnvel senda óskiljanlegan texta, vegna þess að líkanið þarf ekki þessi gögn til að gefa skynsamleg svör.
Fyrir prufu kynninguna báðum við LLM að svara á vinalegan og glaðlegan hátt til að líkja eftir tón vefsíðunnar. Jafnvel þó að gögn séu send á þýsku geturðu haft samskipti bæði á þýsku og ensku.
AI Chatbot svarar á þýsku
AI Chatbot svarar á ensku
Prófaðu forritin okkar á AI kynningarvefsíðunni okkar
Þú getur heimsótt AI kynningarsíðuna okkar til að prófa ofangreind forrit sjálfur. Á síðunni finnur þú líka önnur gervigreind forrit sem við höfum búið til.
Viltu búa til þín eigin gervigreindar forrit?
Ef þú ert tilbúin/nn þá erum við það líka!
Fleiri greinar
Af hverju er opinn hugbúnaður góður valkostur fyrir fyrirtækjalausnir?

Við erum oft spurð að því hvers vegna fyrirtæki velja opinn hugbúnað fram yfir séreignarhugbúnað (e...
MVP nálgun fyrir vefverkefni
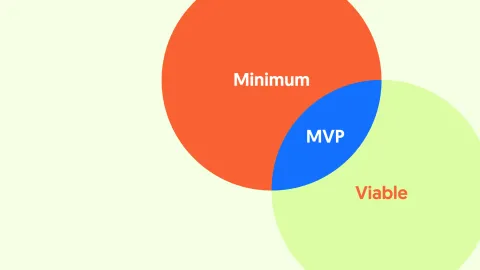
Hjá 1xINTERNET notum við MVP (e. Minimum Viable Product) nálgun til að skila af okkur árangursríkum...